
[ 딥러닝 ] Optimization - part 1
Updated:
Generalization
-
Generalization Gap : 이상과 현실의 괴리
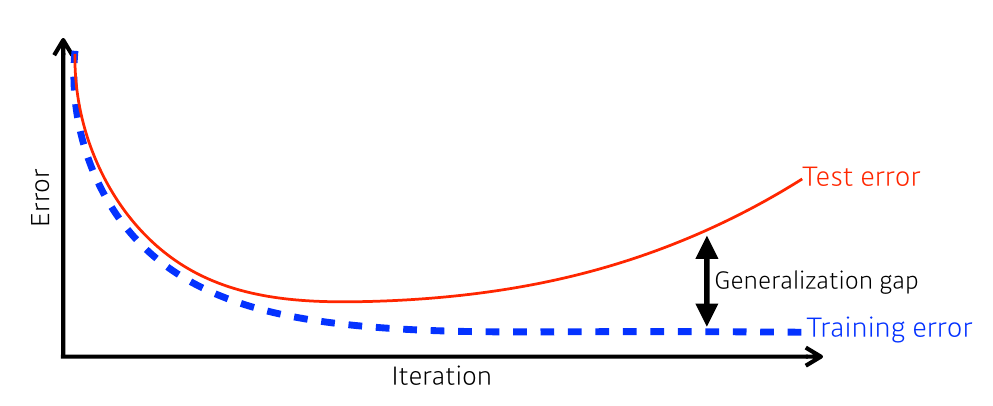
학습과 테스트 간의 간극을 줄이기 위해서는 generalization을 잘 해야 한다! → How?
Under-fitting, Over-fitting
generalization을 잘 하는 방법을 알기 전에 알아야 할 것들
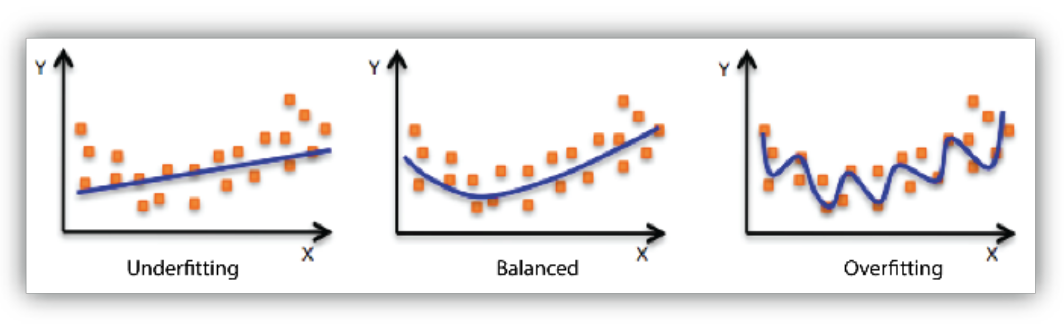
- balanced : 적절하게 근사한 모델
-
under-fitting : 너무 대충 학습해서 근사 못 하는 것. (차원이 너무 낮은 것.)
e.g.) 시험 공부 너무 안 한 상태
-
over-fitting : 너무 많이 학습해서 근사 못 하는 것. (차원이 너무 높은 것.)
e.g.) 너무 이론만 많이 공부한 상태
(K-fold) Cross Validation
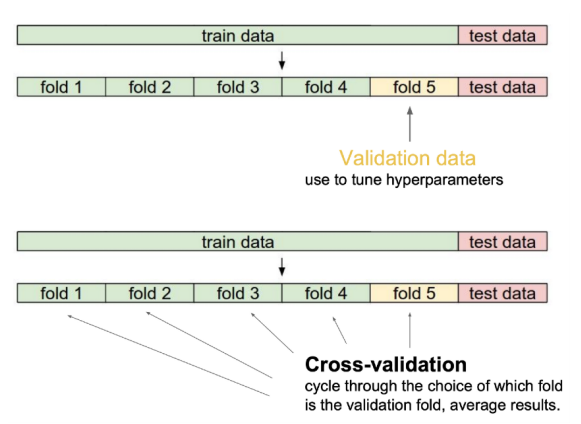
- generalization을 위한 방법 중 하나
- train set을 k개 만큼 균등분할하여 돌아가며 하나씩 validation set, 나머지는 (real) train set으로 사용하는 방식
- validation set? test set?
- validation set : (train 과정 중) hyper-parameter(사람이 설정)를 조정하기 위해 사용
- test set : (train 과정 이후) test할 때 사용
- k번 만큼 학습을 진행하는 것이기 때문에 generalization에 효과적이다.
- validation set? test set?
Bias-Variance Tradeoff
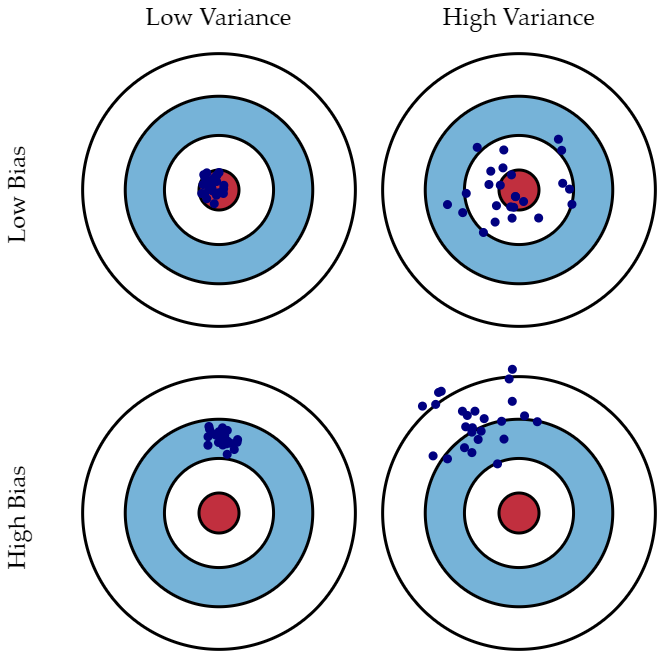
bias
- 예측값이 정답과 얼마나 멀리 떨어져 있는가?
- 데이터 내에 있는 모든 정보를 고려하지 않아 지속적으로 잘못된 것들을 학습하는 경향.
- underfitting과 관계되어 있다.
variance
- 예측값이 얼마나 퍼져있는가?
- 데이터 내 noize까지 잘 잡아내는 highly flexible models에 데이터를 fitting시킴으로써, 실제 현상과 관계 없는 random한 것들까지 학습하는 경향.
- overfitting과 관계되어 있다.
- 예제
- underfitting의 경우
- high-bias : 이 모델은 데이터 내의 모든 정보를 고려하지 못한다.
- low-variance : 새로운 데이터가 들어와도 모델의 형태는 크게 변하지 않을 것이다.
- overfitting의 경우
- low-bias : 이 모델은 주어진 데이터를 잘 설명하고 있다.
- high-variance : 새로운 데이터가 들어오면 모델은 완전히 다른 형태로 변하게 된다.
- underfitting의 경우
- 이상적으로는 high-bias, high-variance 가 좋지만, 실제 동시에 만족하는 것은 거의 불가능하고 좋은 성능을 내기 위해 이런 tradeoff는 반드시 생길 수 밖에 없다.
Bootstrapping
- ramdom sampling with replacement
- 현재 있는 표본에서 추가적으로 복원 추출하고 각 표본에 대한 통계량을 다시 계산하는 것
Bagging, Boosting
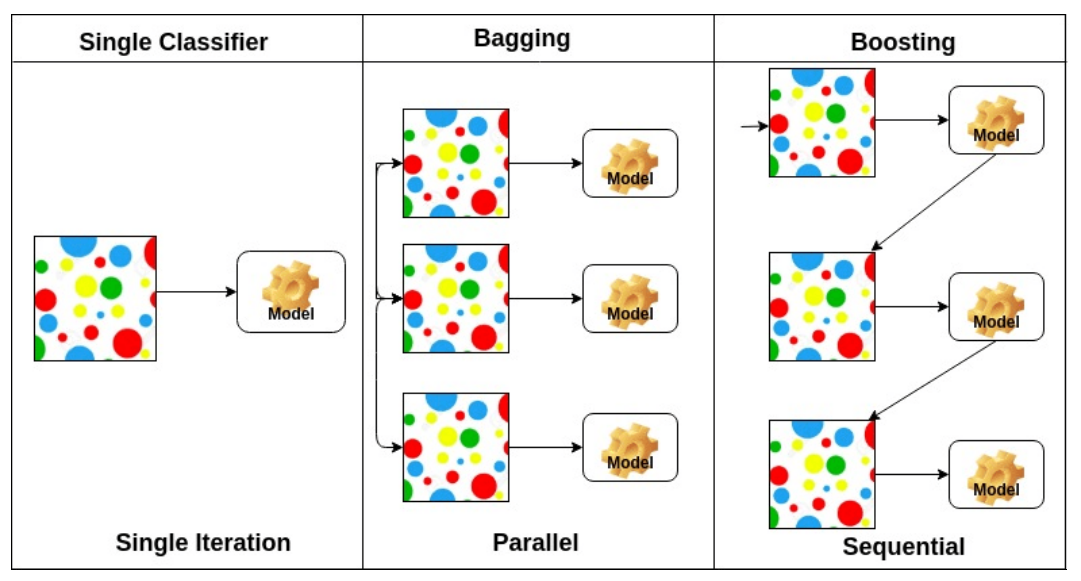
- Bagging (Bootstrapping Aggregating)
- 여러 모델에게 bootstrapping해서 각각에 대한 학습 결과를 집계하는 방법 (parallel)
- Boosting
- 맞추기 어려운 문제를 풀 때 유용하다.
- bootstrapping + 가중치 부여
- 오답 → 높은 가중치, 정답 → 낮은 가중치
- sequential (= 학습 후 나온 결과에 따른 가중치 재분배)