
[ 딥러닝 ] Regularization
Updated:
Early Stopping
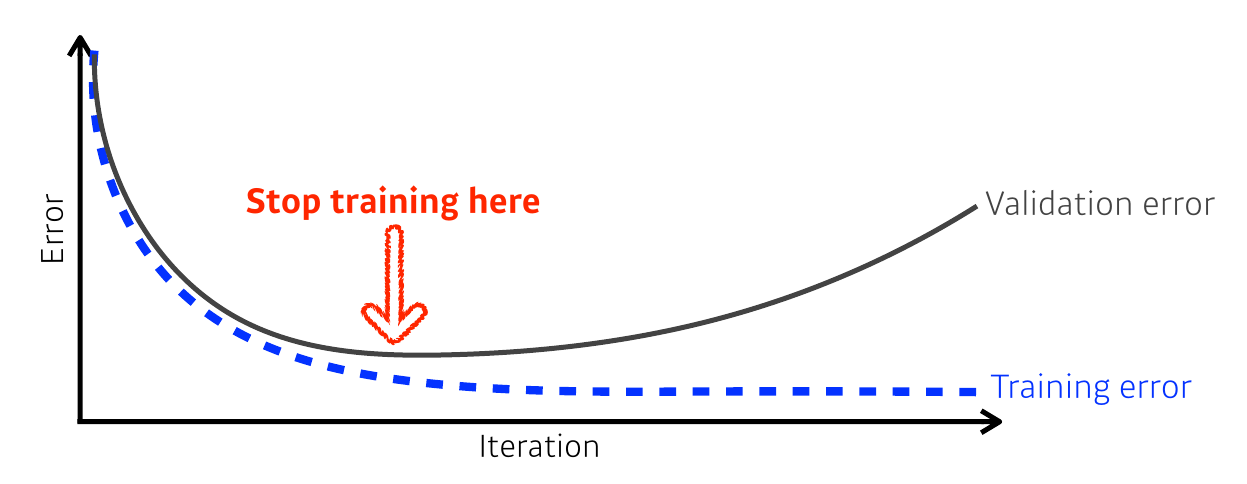
- 적절한 epoch을 설정하는 것은 중요하다.
- 너무 많은 epoch → overfitting
- 너무 적은 epoch → underfitting
- 해결법? 이전 epoch과 비교해 오차가 증가했다면 학습을 중단하자!
Parameter Norm Penalty
\[tot. cost = loss(D;W) + \alpha \frac{1}{2}\|W\|^2_2\]- 기존의 loss에다가 penalty term을 추가해서 weight값이 필요 이상으로 커지는 것을 방지한다.
- $\frac{1}{2}|W|^2_2$ : $L_2$ parameter norm penalty (weight decay)
Data Augmentation
- 데이터가 많을수록 generalization이 잘 된다.
- 하지만 대부분의 상황에선 오히려 데이터가 부족한 경우가 더 많다.
- 이를 해결하기 위한 방법으로 data augmentation을 사용한다.
- rescale, reflection, crop, rotation, translation 등이 있다.
Noise Robustness

- noise에 강건(robust)해지기 위해 input data에 random noise를 넣는 것
Label Smoothing
- Hard label (1 or 0) → Soft label(0~1 사이의 값)
Mix-up

- 두 데이터를 overlap시켜 섞는 것.
CutMix

- 한 데이터의 일부분을 다른 데이터에서 붙여서 섞는 것.
Dropout
- random하게 선택한 일부 뉴런이 동작하지 않게 하는 것
Batch Normalization
Internal Covariate Shift
- layer를 통과할 때 마다 Covariate Shift가 일어나는 현상
- Covariate Shift : 이전 layer의 파라미터 변화로 현재 레이어의 입력 분포가 바뀌는 현상
Batch Normalization
-
학습 시 parameter 조정과 동시에 평균과 분산도 조정한다.
\[\mu_B = \frac{1}{m}\sum_{i=1}^m x_i \\ \, \\ \sigma_B^2 = \frac{1}{m}\sum_{i=1}^m(x_i-\mu_B)^2 \\ \, \\ \hat{x}_i = \frac{x_i-\mu_B}{\sqrt{\sigma_B^2 + \epsilon}}\]